Day 21: Search engine
Previously on symfony
With AJAX interactions, web services, RSS feed, a hat ful of site management features, and a growing number or users, askeet has almost all that a web 2.0 application could ask for. The symfony community debated about what could be added on top of that, in order to make askeet a real killer application.
Some of the suggestions included features that were already planned for initially. Others concerned small additions that will take only a couple minutes to implement, and that will probably be added shortly after the 1.0 release. Askeet aims to be a living open-source application, and you can start raising tickets or proposing evolutions in the askeet trac system. And you can also contribute patches and adapt or extend the application as you wish. But please wait a few more days, for the advent calendar has some more surprises for you before Christmas.
How to build a search engine?
The most popular suggestion about the 21st day addition proved to be a search engine.
If the Zsearch extension (a PHP implementation of the Lucene search engine from Apache) had already been released by Zend, this would have been a piece of cake to implement. Unfortunately, Zend seems to take longer than expected to launch their PHP framework, so we need to find another solution.
Integrating a foreign library (like, for instance, mnoGoSearch) would probably take more than one hour, and lots of custom adaptations would be necessary to obtain a good result for the askeet specific content. Plus, foreign search libraries are often platform or database dependant, and not all of them are open-source, and that's something we don't want for askeet.
The MySQL database offers a full-text indexation and search for text content, but it is restricted to MyISAM tables. Once again, basing our search engine on a database-specific component would limit the possible uses of the askeet application, and we want to do everything to preserve the large compatibility it has so far.
The only alternative left is to develop a full-text PHP search engine by ourselves. And we have less than one hour, so we'd better get started.
Word index
The first step is to build a search index. The index can be seen as a table indexing all occurrences of a particular word. For example, if question #34 has the following characteristics:
- Title: What is the best Zodiac sign for my child?
- Body: My husband doesn't care about Zodiac signs for our next child, but we already have a Cancer girl and an Aries boy, and they get along with each other like hell. My mother-in-law didn't express any preference, so I am completely free to choose the Zodiac sign of my next baby. What do you think?
- Tags: zodiac, real life, family, children, sign, astrology, signs
An index has to be created to list the words of this question, so that a search engine can find it.
Index table
The index should look like:
| id | word | count |
|---|---|---|
| 34 | sign | 4 |
| 34 | zodiac | 4 |
| 34 | child | 2 |
| 34 | hell | 1 |
| 34 | ... | ... |
A new SearchIndex table is added to the askeet schema.xml before rebuilding the model:
<table name="ask_search_index" phpName="SearchIndex"> <column name="question_id" type="integer" /> <foreign-key foreignTable="ask_question" onDelete="cascade"> <reference local="question_id" foreign="id"/> </foreign-key> <column name="word" type="varchar" size="255" /> <index name="word_index"> <index-column name="word" /> </index> <column name="weight" type="integer" /> </table>
The onDelete attribute ensures that the deletion of a question will lead to the deletion of all the records in the SearchIndex table related to this question, as explained yesterday.
Splitting phrases into words
The input content that will be used to build the index is a set of sentences (question title and body) and tags. What is eventually needed is a list of words. This means that we need to split the sentences into words, ignoring all punctuation, numbers, and putting all words to lowercase. The str_word_count() PHP function will do the trick:
// split into words $words = str_word_count(strtolower($phrase), 1); ...
Stop words
Some words, like "a," "of," "the," "I,", "it", "you," and "and", have to be ignored when indexing some text content. This is because they have no distinctive value, they appear in almost every text content, they slow down a text search and make it return a lot of poorly interesting results that have nothing to do with a user's query. They are known as stop words. The stop words are specific to a given language.
For the askeet search engine, we will use a custom list of stop words. Add the following method to the askeet/lib/myTools.class.php class:
public static function removeStopWordsFromArray($words) { $stop_words = array( 'i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', 'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', 'her', 'hers', 'herself', 'it', 'its', 'itself', 'they', 'them', 'their', 'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this', 'that', 'these', 'those', 'am', 'is', 'are', 'was', 'were', 'be', 'been', 'being', 'have', 'has', 'had', 'having', 'do', 'does', 'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if', 'or', 'because', 'as', 'until', 'while', 'of', 'at', 'by', 'for', 'with', 'about', 'against', 'between', 'into', 'through', 'during', 'before', 'after', 'above', 'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off', 'over', 'under', 'again', 'further', 'then', 'once', 'here', 'there', 'when', 'where', 'why', 'how', 'all', 'any', 'both', 'each', 'few', 'more', 'most', 'other', 'some', 'such', 'no', 'nor', 'not', 'only', 'own', 'same', 'so', 'than', 'too', 'very', ); return array_diff($words, $stop_words); }
Stemming
The first thing that you should notice in the example question given above is that words having the same radical should be seen as a single one. 'Children' should increase the weight of 'child', as should 'sign' do for 'signs'. So before indexing words, they have to be reduced to their greatest common divisor, and in linguistics vocabulary, this is called a stem, or "the base part of the word including derivational affixes but not inflectional morphemes, i. e. the part of the word that remains unchanged through inflection".
There are lots of rules to transform a word into its stem, and these rules are all language-dependant. One of the best stemming techniques for the English language so far is called the Porter Stemming Algorithm and, as we are very lucky, it has been ported to PHP5 in an open-source script available from tartarus.org.
The PorterStemmer class provides a ::stem($word) method that is perfect for our needs. So we can write a method, still in myTools.class.php, that turns a phrase into an array of stem words:
[php]
public static function stemPhrase($phrase)
{
// split into words
$words = str_word_count(strtolower($phrase), 1);
// ignore stop words
$words = myTools::removeStopWordsFromArray($words);
// stem words
$stemmed_words = array();
foreach ($words as $word)
{
// ignore 1 and 2 letter words
if (strlen($word) <= 2)
{
continue;
}
$stemmed_words[] = PorterStemmer::stem($word, true);
}
return $stemmed_words;
}
Of course, you have to put the PorterStemmer.class.php in the same askeet/lib/ directory for this to work.
Giving weight to words
The search results have to appear in order of pertinence. The questions that are more tightly related to the words entered by the user have to appear first. But how can we translate this idea of pertinence into an algorithm? Let's write a few basic principles:
- If a searched word appears in the title of a question, this question should appear higher in a search result than another one where the word appears only in the body.
- If a searched word appears twice in the content of a question, the search result should show this question before others where the word appears only once.
That's why we need to give weight to words according to the part of the question they come from. As the weight factors have to be easily accessible, to make them vary if we want to fine tune our search engine algorithm, we will put them in the application configuration file (askeet/apps/frontend/config/app.yml):
all:
...
search:
body_weight: 1
title_weight: 2
tag_weight: 3
In order to apply the weight to a word, we simply repeat the content of a string as many times as the weight factor of its origin:
... // question body $raw_text = str_repeat(' '.strip_tags($question->getHtmlBody()), sfConfig::get('app_search_body_weight')); // question title $raw_text .= str_repeat(' '.$question->getTitle(), sfConfig::get('app_search_title_weight')); ...
The basic weight of the words will be given by their number of occurrences in the text. The array_count_values() PHP function will help us for that:
... // phrase stemming $stemmed_words = myTools::stemPhrase($raw_text); // unique words with weight $words = array_count_values($stemmed_words);
Updating the index
The index has to be updated each time a question, tag or answer is added. The MVC architecture makes it easy to do, and you have already seen how to override a save() method in a class of the Model with a transaction, for instance during day four. So the following should not surprise you. Open the askeet/lib/model/Question.php file and add in:
public function save($con = null) { $con = sfContext::getInstance()->getDatabaseConnection('propel'); try { $con->begin(); $ret = parent::save($con); $this->updateSearchIndex(); $con->commit(); return $ret; } catch (Exception $e) { $con->rollback(); throw $e; } } public function updateSearchIndex() { // delete existing SearchIndex entries about the current question $c = new Criteria(); $c->add(SearchIndexPeer::QUESTION_ID, $this->getId()); SearchIndexPeer::doDelete($c); // create a new entry for each of the words of the question foreach ($this->getWords() as $word => $weight) { $index = new SearchIndex(); $index->setQuestionId($this->getId()); $index->setWord($word); $index->setWeight($weight); $index->save(); } } public function getWords() { // body $raw_text = str_repeat(' '.strip_tags($this->getHtmlBody()), sfConfig::get('app_search_body_weight')); // title $raw_text .= str_repeat(' '.$this->getTitle(), sfConfig::get('app_search_title_weight')); // title and body stemming $stemmed_words = myTools::stemPhrase($raw_text); // unique words with weight $words = array_count_values($stemmed_words); // add tags $max = 0; foreach ($this->getPopularTags(20) as $tag => $count) { if (!$max) { $max = $count; } $stemmed_tag = PorterStemmer::stem($tag); if (!isset($words[$stemmed_tag])) { $words[$stemmed_tag] = 0; } $words[$stemmed_tag] += ceil(($count / $max) * sfConfig::get('app_search_tag_weight')); } return $words; }
We also have to update the question index each time a tag is added to it, so override the save() method of the Tag model object as well:
public function save($con = null) { $con = sfContext::getInstance()->getDatabaseConnection('propel'); try { $con->begin(); $ret = parent::save($con); $this->getQuestion()->updateSearchIndex(); $con->commit(); return $ret; } catch (Exception $e) { $con->rollback(); throw $e; } }
Test the index builder
The index is ready to be built. Initialize it by populating the database again:
$ php batch/load_data.php
You can inspect the SearchIndex table to check if the indexing went all well:
| id | word | weight |
|---|---|---|
| 10 | blog | 6 |
| 9 | offer | 4 |
| 8 | girl | 3 |
| 8 | rel | 3 |
| 8 | activ | 3 |
| 10 | activ | 3 |
| 9 | present | 3 |
| 9 | reallif | 3 |
| 11 | test | 3 |
| 12 | test | 3 |
| 13 | test | 3 |
| 8 | shall | 3 |
| 8 | tonight | 2 |
| 8 | girlfriend | 2 |
| .. | ..... | .. |
The search function
AND or OR?
We want the search function to manage both 'AND' and 'OR' searches. For instance, if a user enters 'family zodiac', he (she?) must be given the choice to look only for the questions where both the two terms appear (that's an 'AND'), or for all the questions where at least one of the term appears (that's an 'OR'). The trouble is that these two options lead to different queries:
// OR query SELECT DISTINCT question_id, COUNT(*) AS nb, SUM(weight) AS total_weight FROM ask_search_index WHERE (word = "family" OR word = "zodiac") GROUP BY question_id ORDER BY nb DESC, total_weight DESC // AND query SELECT DISTINCT question_id, COUNT(*) AS nb, SUM(weight) AS total_weight FROM ask_search_index WHERE (word = "family" OR word = "zodiac") GROUP BY question_id HAVING nb = 2 ORDER BY nb DESC, total_weight DESC
Thanks to the HAVING keyword (explained, for instance, at w3schools), the AND SQL query is only one line longer than the OR one. As the GROUP BY is on the id column, and because there is only one index occurrence for a given word in a question, if a question_id is returned twice, it is because the question matches both the 'family' and 'zodiac' term. Neat, isn't it?
The search method
For the search to work, we need to apply the same treatment to the search phrase as to the content, so that the words entered by the user are reduced to the same kind of stem that lies in the index. Since it returns a set of questions without any foreign constraint, we decide to implement it as a method of the QuestionPeer object.
The search results need to be paginated. As we use a complex request, the sfPropelPager object cannot be employed here, so we will do a pagination by hand, using an offset.
There is one more thing to remember: askeet is made to work with universes (that was the subject of the eighteenth day tutorial). This means that a search function must only return the questions tagged with the current app_permanent_tag if the user is browsing askeet in a universe.
All these conditions make the SQL query slightly more difficult to read, but not much different from the ones described above:
public static function search($phrase, $exact = false, $offset = 0, $max = 10) { $words = array_values(myTools::stemPhrase($phrase)); $nb_words = count($words); if (!$words) { return array(); } $con = sfContext::getInstance()->getDatabaseConnection('propel'); // define the base query $query = ' SELECT DISTINCT '.SearchIndexPeer::QUESTION_ID.', COUNT(*) AS nb, SUM('.SearchIndexPeer::WEIGHT.') AS total_weight FROM '.SearchIndexPeer::TABLE_NAME; if (sfConfig::get('app_permanent_tag')) { $query .= ' WHERE '; } else { $query .= ' LEFT JOIN '.QuestionTagPeer::TABLE_NAME.' ON '.QuestionTagPeer::QUESTION_ID.' = '.SearchIndexPeer::QUESTION_ID.' WHERE '.QuestionTagPeer::NORMALIZED_TAG.' = ? AND '; } $query .= ' ('.implode(' OR ', array_fill(0, $nb_words, SearchIndexPeer::WORD.' = ?')).') GROUP BY '.SearchIndexPeer::QUESTION_ID; // AND query? if ($exact) { $query .= ' HAVING nb = '.$nb_words; } $query .= ' ORDER BY nb DESC, total_weight DESC'; // prepare the statement $stmt = $con->prepareStatement($query); $stmt->setOffset($offset); $stmt->setLimit($max); $placeholder_offset = 1; if (sfConfig::get('app_permanent_tag')) { $stmt->setString(1, sfConfig::get('app_permanent_tag')); $placeholder_offset = 2; } for ($i = 0; $i < $nb_words; $i++) { $stmt->setString($i + $placeholder_offset, $words[$i]); } $rs = $stmt->executeQuery(ResultSet::FETCHMODE_NUM); // Manage the results $questions = array(); while ($rs->next()) { $questions[] = self::retrieveByPK($rs->getInt(1)); } return $questions; }
The method returns a list of Question objects, ordered by pertinence.
The search form
The search form has to be always available, so we choose to put it in the sidebar. As there are two distinct sidebars, they should include the same partial:
// add to defaultSuccess.php and questionSuccess.php in askeet/apps/frontend/modules/sidebar/templates/ <h2>find it</h2> <?php include_partial('question/search') ?> // create the following askeet/apps/frontend/modules/question/templates/_search.php fragment <?php echo form_tag('@search_question') ?> <?php echo input_tag('search', htmlspecialchars($sf_params->get('search')), array('style' => 'width: 150px')) ?> <?php echo submit_tag('search it', 'class=small') ?> <?php echo checkbox_tag('search_all', 1, $sf_params->get('search_all')) ?> <label for="search_all" class="small">search with all words</label> </form>
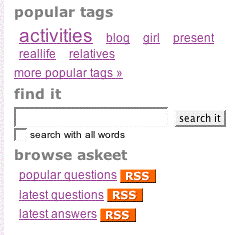
The @search_question rule has to be defined in the routing.yml:
search_question:
url: /search/*
param: { module: question, action: search }
Do you know what this question/search action does? Almost nothing, since most of the work is handled by the QuestionPeer::search() method described above:
public function executeSearch () { if ($this->getRequestParameter('search')) { $this->questions = QuestionPeer::search($this->getRequestParameter('search'), $this->getRequestParameter('search_all', false), ($this->getRequestParameter('page', 1) - 1) * sfConfig::get('app_search_results_max'), sfConfig::get('app_search_results_max')); } else { $this->redirect('@homepage'); } }
The action has to translate a page request parameter into an offset for the ::search() method. The app_search_results_max is the number of results per page, and as usual, it is an application parameter defined in the app.yml file:
all:
search:
results_max: 10
Display the search result
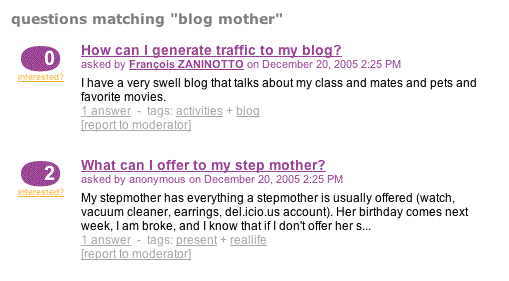
The hardest part of the job is done, we just have to display the search result in a askeet/apps/frontend/modules/question/templates/searchSuccess.php. As we didn't implement a real pagination to keep the query light, the template has no information about the total number of results. The pagination will just display a 'more results' link at the bottom of the result list if the number of results equals the maximum of results per page:
<?php use_helper('Global') ?> <h1>questions matching "<?php echo htmlspecialchars($sf_params->get('search')) ?>"</h1> <?php foreach($questions as $question): ?> <?php include_partial('question/question_block', array('question' => $question)) ?> <?php endforeach ?> <?php if ($sf_params->get('page') > 1 && !count($questions)): ?> <div>There is no more result for your search.</div> <?php elseif (!count($questions)): ?> <div>Sorry, there is no question matching your search terms.</div> <?php endif ?> <?php if (count($questions) == sfConfig::get('app_search_results_max')): ?> <div class="right"> <?php echo link_to('more results »', '@search_question?search='.$sf_params->get('search').'&page='.($sf_params->get('page', 1) + 1)) ?> </div> <?php endif ?>
Ah, yes, this is the final surprise. We refactored a little the question templates to create a _question_block.php question block, as the code was reused in more than one place. Have a look at this fragment in the source repository, there is nothing new in it. But it helps us to keep the code clean.
See you Tomorrow
It took us about one hour to build a good search engine, perfectly adapted to our needs. It is light, fast and efficient. It returns pertinent results. Would you want to integrate an external library to do the same job without any possibility to tweak it?
If not, you are probably getting to think the symfony way. If you understood this tutorial, you can probably add to the search engine the indexing of answers to a question. Questions and suggestions are welcome in the askeet forum. And most of all, don't create new questions on askeet if a similar question has already been asked: Now there is a search engine, you have no excuse!
This work is licensed under the Creative Commons Attribution-Noncommercial-No Derivative Works 3.0 Unported License license.